The Myth of “Click Depth”
Referring to Click Depth, the majority of SEO experts measure it using two simplified models: the minimum link count from the homepage or the perceived physical file structure.
While they give a quick metric, they mostly do not give precise information about the link equity flow and crawler prioritization. A critical service page might be three clicks away, but due to chaotic internal linking or unknown bot preferences, the crawler may encounter it only after processing hundreds of pages. On the other side, a page with no visible link but mentioned by hreflang, for example, may be visited immediately.
While tools like Screaming Frog offer reliable visualizations for these established models, they fundamentally fail to answer the most critical question regarding equity distribution.
We need a method to see the site through the eyes of the bot, which prioritizes pages based on links found during the crawl sequence.
Time-Based Crawl Path Framework
Our audit strips away theoretical click depth and assigns a definitive Crawl Level to every URL based on its discovery time in the crawl log (the Crawl Timestamp).
- Level 1 (L1): The initial set of URLs found (e.g., the homepage).
- Level N (LN): Every subsequent URL is assigned an incremental level based on its time group.
This process transforms the messy, sequential crawl log into a structured, chronological hierarchy. This fixed framework is the foundation for analyzing link preference.
For a practical demonstration, the proof‑of‑concept app is available here: https://crawl-time-framework.streamlit.app/
Full Path Tracing
Once every page has a stable Level, we use the outlinks from already crawled pages to perform a full back-trace. For each page, we recursively follow its assigned Parent link (the lowest-Level page that linked to it) all the way back to the Root (L1).
This generates an auditable, Level-by-Level path, revealing the specific historical sequence the bot used to reach that page.
This represents a single illustrative path per page. In reality, multiple parent links may exist, and combining data from many crawls allows calculation of link-priority probabilities based on different discovery timestamps.
How this is accomplished
Perform a Screaming Frog crawl of the website with your preferred settings. Extract two tables: one with all internal HTML URLs, and a second with all their outlinks. The processing, level assignment, and full path tracing were implemented using a Python script.
Observed Crawl Path
The Full Path Trace represents one empirically recorded route the crawler took to each node.
· The Parent link assigned to a URL is a link from the lowest-Level page processed earliest in this crawl.
· Across the site crawl, the result is a combination of many such routes, forming a tree that reflects a combination of probably observed paths.
· This tree can be visualized to show how the crawler progressed through levels over time.
Small Site Test Environment
A small site has been used as the real test environment for our crawl experiments. It has a few categories, around 40 posts at the root level, and 3–4 main pages, representing a standard blog structure.
The homepage contains standard links to 2–3 pages and to the categories including also a grid of the last six posts (image, title…).
The posts are linked only through standard blog and category listings, with no additional in-post links.
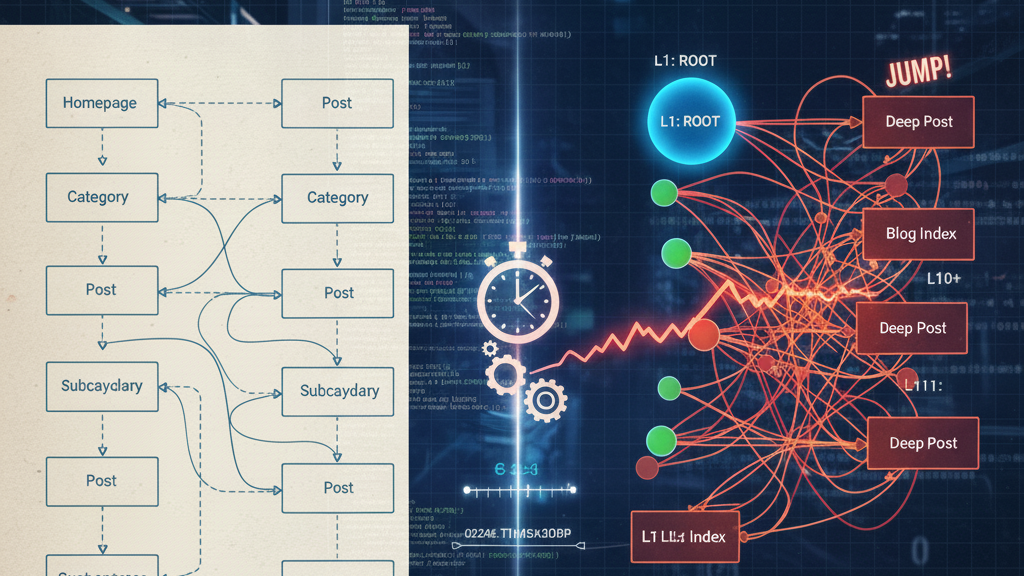
Screaming Frog visualizations show a neat, well-clustered structure: homepage → categories → posts, suggesting evenly distributed topical clusters.

In reality, the crawler may experience a different sequence. Posts at the root level or deep in the blog index may be reached earlier or later than expected due to link order and discovery timing. This highlights that a visually tidy crawl map does not necessarily reflect actual crawler paths, link equity distribution, or crawl prioritization.
Example of Structural Confusion
An ideal path follows a gradual, linear progression: L1 → L2 → L3 → L4. However, the trace often reveals structural problems, such as the alarming “Link Equity Jump”:
L1: ROOT L2: Category L3: Post L4: Other Category L5: Blog Index L11: Other Post L15: Deep Post
Impact:
After L3 (Post), the crawler moves upward toward L4 (Other Category) and then continues to L5 (Blog Index), a semantic jump that breaks the expected topical flow.
The other aspect is a structural jump, bypassing intermediate levels. Subsequent post-to-post timestamp jumps (L11 → L15) further distort the crawl sequence.
These jumps can delay link equity distribution to intermediate pages, disrupt logical topical clustering, and indicate suboptimal internal linking that reduces crawl efficiency.
Result Data: Table, Visualization, and Path Logs

The most powerful insight comes from visualizing the data. By using the calculated Levels for vertical positioning in a graph, we produce an immediate, scannable representation of the site structure.
- Nodes colored by Level: Shallow pages (L1–L3) are easily distinguishable from deep pages (L10+).
- Fixed verticality: The graph enforces that all L3 nodes appear above L4 nodes, making depth relationships instantly clear.
Conclusion: Actionable Audit Insights
This audit process moves beyond simple metrics by providing empirical data on how the crawler actually navigates your site. Based on the results, you can analyze patterns such as which types of links the bot prioritizes, which pages are repeatedly delayed in discovery, which pages may be effectively “lost” in the crawl sequence, and which pages load slowly and affect crawl efficiency. These insights help identify structural and linking issues that influence link equity distribution and overall site performance.
Future Directions
- Choosing start and end points: Allow flexibility in defining crawl origins and target URLs to analyze specific paths.
- Multiple paths per destination: Visualize different routes a crawler can take to reach the same URL.
- Time-step analysis: Track the exact discovery time of each URL during the crawl. This allows you to see how the crawler progresses across the site over time, spot pages that are reached later than expected, and identify potential bottlenecks or delays in link equity flow.
Comparing multiple crawls can reveal consistent patterns or irregularities in how the bot navigates your site.
I use Screaming Frog simply as a reliable and widely adopted crawler to collect empirical crawl data. The framework is not designed to replicate Googlebot’s full behavior or prioritization model. Googlebot uses many additional signals beyond links and crawls at a massive scale in parallel.
The purpose of the Crawl Time Framework is different. It provides a reproducible, site-only view of link discovery order based strictly on crawl timestamps. Although both Googlebot and Screaming Frog crawl in parallel, this framework does not impose a strict linear sequence. Instead, URLs discovered within the same time window are grouped into Levels, where each Level represents a parallel batch of URLs found at the same stage of the crawl.
By structuring the crawl this way, we can trace parent paths and observe how internal links actually introduce URLs to the crawler over time. This makes internal link sequencing auditable and highlights anomalies—such as equity jumps or delayed discovery—that are invisible in traditional click-depth metrics or static crawl visualizations.
BTW, this is just an idea and can be extended.
For example, combined with server log data to collect information on known Googlebot behavior patterns, it would be possible to apply probability coefficients to different paths based on observed Google preferences.
Rather than claiming a single “true” crawl path, the model can express which paths are more or less likely, grounded in real discovery timing and reinforced by log evidence. In this way, the framework evolves from a diagnostic snapshot into a probabilistic model of crawl behavior, while remaining transparent, testable, and site-focused.
The framework isn’t intended to replicate Googlebot fully. It represents link flow using site-only signals and crawl timestamps to structure discovery order.
URLs aren’t assigned a strict linear order. Levels group URLs discovered in the same timestamp batch, reflecting parallel crawl stages rather than oversimplifying prioritization.
The method doesn’t replicate Googlebot’s prioritization. It provides a reproducible, timestamp-based view of link discovery, highlighting internal link anomalies and “equity jumps” without misrepresenting actual importance.
ILR is relevant. The Crawl Time Framework complements internal link rank models: ILR shows relative equity flow, while this framework shows timestamp-based discovery order. Levels highlight sequencing, anomalies, and delayed discovery that semantic trees like Screaming Frog’s force-directed graphs may not capture. Screenshots in the article compare both approaches.

Marin Popov – SEO Consultant with over 15 years of experience in the digital marketing industry. SEO Expert with exceptional analytical skills for interpreting data and making strategic decisions. Proven track record of delivering exceptional results for clients across diverse industries.
Leave a Reply